
How to Build a Seamless Data Pipeline that Accelerates Insights in 10-Steps
Data scientists still spend up to 80% of their time extracting, cleaning, and transforming data, even when using various machine learning algorithms, rather than building models or generating the value their job entails.
The consequences can be expensive. For instance, Unity Technologies lost approximately $110 million in revenue when corrupt training data poisoned their ad-targeting algorithms, causing their stock to drop 37%.
Similar pipeline failures have led to multimillion-dollar regulatory fines, incorrect business decisions, and eroded trust.
The solution lies in building a seamless data pipeline; one that moves data cleanly and consistently from source systems directly into your data science workflow, while you intensively work on the latter models and processes.
In this guide, you’ll learn practical steps to design and implement an efficient data pipeline that eliminates bottlenecks and accelerates insights.
The 10-Step Golden Rule for Building a Seamless Data Pipeline
A data pipeline is a series of steps that move data from a database to data scientists for analysis. The more seamless the process, the quicker the data comes out of the analysis for actual implementation, such as refining ad targeting, optimizing search intent for higher engagement, designing growth-engineering tactics, etc.
Building a seamless data pipeline involves several steps, including data extraction, transformation, storage, and analysis. Automating this process with core human input and principled monitoring helps speed up decision-making while significantly improving the quality of usable data.
Here is a step-by-step guide to building a seamless data pipeline.
Step 1: Define the Purpose of the Pipeline
Before building anything, start by identifying what the pipeline needs to achieve. Is it meant for reporting, machine learning, real-time monitoring, or business intelligence?
Defining the purpose helps determine what data to collect, how often it should be updated, and what level of accuracy and speed is required.
At this stage, these things should be considered.
|
Key Consideration |
Why It Matters |
Examples / Questions to Ask |
|
Business Problem to Solve |
Ensures the pipeline delivers real value and aligns with organizational goals |
What specific issue are we solving? (e.g., delayed sales reports, inaccurate customer predictions) |
|
Target Users / Teams |
Tailors the pipeline to the needs and technical level of the people who will consume the data |
Who will use this data? (e.g., Marketing team, Data Scientists, Executive leadership) |
|
Processing Type |
Determines the architecture — batch vs. streaming affects tools, cost, and complexity |
Do we need batch processing (daily/ hourly) or real-time streaming? |
Step 2: Identify and Connect Data Sources
The next step is to locate the systems where your data currently lives. These sources may include relational databases, cloud storage, APIs, logs, spreadsheets, or third-party applications.
Once identified, establish secure and reliable connections to these sources.

Step 3: Extract the Data Efficiently
After connecting to the sources, the pipeline must pull data from them in a structured way. This is the extraction phase.
Efficient extraction reduces unnecessary load on production systems and ensures the pipeline remains scalable as data volumes grow.
Depending on your use case, extraction can happen through three processes.
|
Extraction Method |
Description |
Best For |
Key Benefits |
|
Batch Extraction |
Data is pulled in large groups at scheduled intervals (e.g., hourly, daily, or weekly) |
Reporting, daily dashboards, non-urgent analytics |
Simple to implement, lower system load |
|
Incremental Extraction |
Only new or changed records are extracted since the last run |
Slowly changing data, large datasets |
Faster, reduces redundancy, saves resources |
|
Real-time Streaming |
Data is extracted continuously as soon as it is generated |
Live monitoring, fraud detection, real-time ML |
Up-to-date insights, immediate action |
Step 4: Clean and Transform the Data
Raw data is rarely ready for analysis, often containing duplicates, missing values, inconsistent formats, or irrelevant fields.
This step ensures the data is accurate, consistent, and useful for downstream analytics or machine learning models.

Step 5: Choose the Right Storage Destination
Once data has been transformed, it needs to be stored in a place where analysts and data scientists can access it easily. The destination depends on how the data will be used.
Choosing the right destination improves performance and makes the workflow smoother for end users.
Common options include
|
Storage Destination |
Best For |
Data Type |
Key Advantages |
Typical Use Cases |
|
Data Warehouse |
Structured analytics & business intelligence |
Highly structured, cleaned data |
Fast querying, optimized for analytics |
Dashboards, reporting, BI tools |
|
Data Lake |
Large volumes of raw or semi-structured data |
Raw, semi-structured, unstructured |
High scalability, stores everything |
Data exploration, archiving, big data |
|
Feature Store |
Machine learning model training & serving |
Engineered features |
Reusability, consistency across models |
ML pipelines, recommendation systems |
|
Analytical Database |
High-speed querying and real-time analytics |
Structured & semi-structured |
Extremely fast query performance |
Ad-hoc analysis, real-time dashboards |
Step 6: Automate the Pipeline Workflow
A seamless pipeline should not depend on manual effort. Automation is what turns a data process into a reliable system.
Moreover, workflow orchestration helps coordinate each stage, ensuring data moves consistently from source to destination.
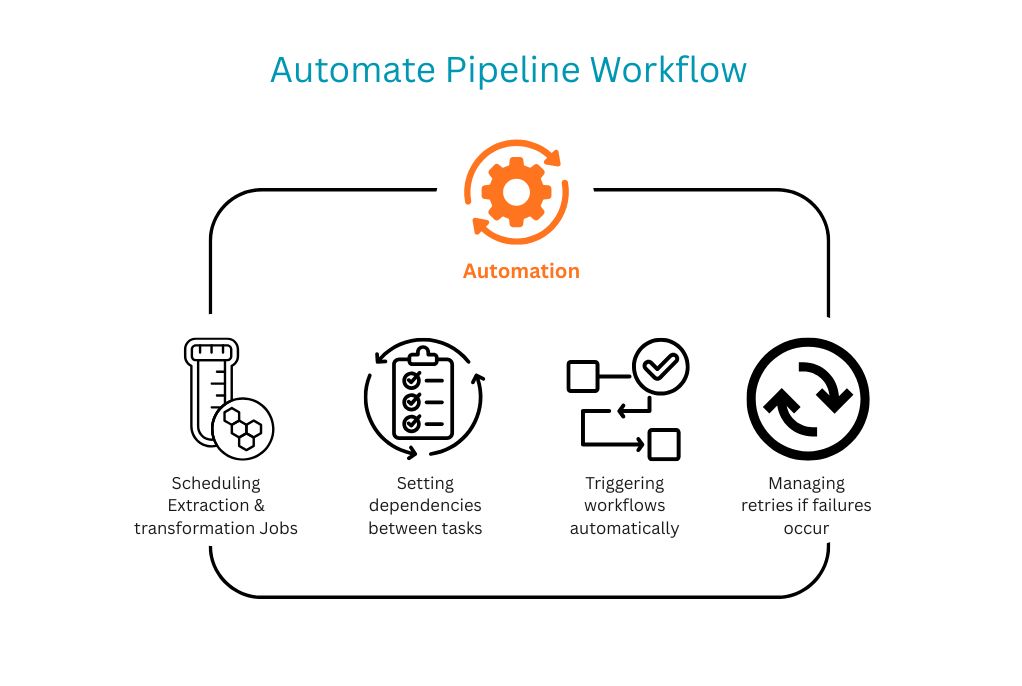
Step 7: Monitor Performance and Data Quality
Even a well-designed pipeline can fail if it is not monitored properly. Data pipelines need continuous visibility to ensure they are working as expected.
Monitoring helps teams catch problems early before they affect reporting, models, or business decisions.
|
Monitoring Aspect |
What It Tracks |
Why It Matters |
Potential Alerts / Issues |
|
Job Success & Failure Rates |
Success/failure of each pipeline run |
Identifies broken jobs quickly |
High failure rate, repeated errors |
|
Pipeline Execution Time |
How long does the pipeline take to complete |
Detects performance degradation over time |
Sudden slowdowns or timeouts |
|
Data Freshness |
How recent the data is (age of the latest record) |
Ensures data is up-to-date for decision-making |
Stale data, delayed updates |
|
Record Counts |
Number of records processed vs. expected |
Spots missing or unexpected data volumes |
Drop in records, sudden spikes |
|
Schema Changes |
Changes in source data structure |
Prevents downstream breakage |
New columns, missing fields, type changes |
|
Data Quality Issues |
Anomalies like nulls, duplicates, and outliers |
Maintains trust and accuracy in analytics |
High null rate, invalid values, duplicates |
Step 8: Build for Scalability
As organizations grow, so does their data. A pipeline that works for small volumes today may struggle tomorrow if it is not designed with scale in mind. Scalability ensures the pipeline continues to perform without major redesigns.
To make the pipeline scalable, it is necessary to implement these things.

Step 9: Secure the Data Pipeline
Because pipelines often handle sensitive business or customer data, security must be built in from the start rather than added later.
A secure pipeline protects both the organization and the integrity of the data science process.
The best security practices are,
|
Security Practice |
Description |
Why It Matters |
|
Encryption |
Encrypt data both in transit and at rest |
Protects data from unauthorized access if intercepted or breached |
|
Role-Based Access Control (RBAC) |
Restrict access using roles and permissions |
Ensures only authorized users can view or modify data |
|
Credential Rotation |
Regularly rotate API keys, passwords, and access tokens |
Reduces risk from compromised or leaked credentials |
|
Data Masking / Anonymization |
Mask or anonymize sensitive fields (e.g., PII, credit card numbers) |
Protects privacy and helps comply with regulations like GDPR/CCPA |
|
Auditing & Logging |
Track and log all pipeline activities and access attempts |
Enables detection of suspicious behavior and supports compliance |
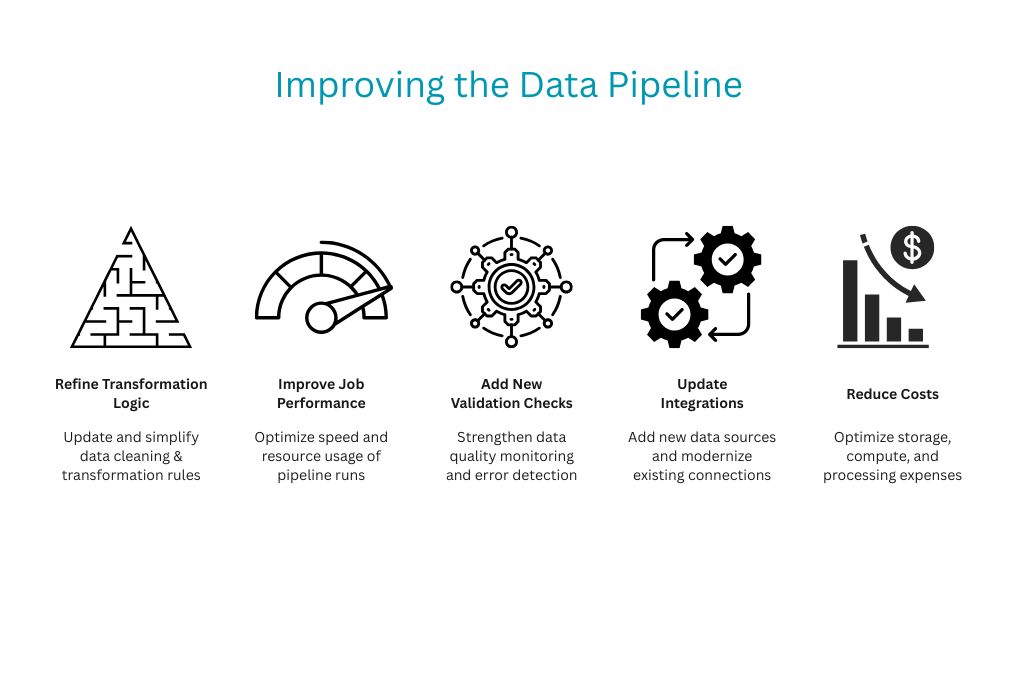
Step 10: Continuously Improve the Pipeline
Building a data pipeline is not a one-time task. As business needs evolve, the pipeline must adapt to new sources, larger datasets, and changing analytical goals.
The best pipelines are maintainable, flexible, and aligned with business growth.
Challenges in Building a Seamless Data Pipeline
While building a seamless data pipeline may seem straightforward, there are several challenges along the way.
For example, data silos can make it difficult to integrate information from different sources, leading to gaps in analysis. Additionally, regulations such as the GDPR and the CCPA require strict measures to ensure data is handled responsibly.
|
Challenge |
Description |
Impact on Pipeline |
|
Data Silos |
Data is scattered across departments, systems, and platforms |
Makes integration difficult and creates gaps in analysis |
|
Scalability Issues |
Growing data volumes overwhelm legacy systems and infrastructure |
Causes performance degradation and higher costs |
|
Data Quality |
Inconsistent, incomplete, or inaccurate data at scale |
Leads to unreliable insights and wrong decisions |
|
Compliance & Security |
Meeting regulations like GDPR and CCPA while protecting sensitive data |
Increases complexity and risk of penalties |
|
Real-time Processing |
Handling and processing data streams in real time |
Requires advanced tools and adds technical complexity |
Conclusion
A seamless data pipeline is the foundation of any effective data science workflow and data-driven decision-making.
By following a structured, step-by-step approach, organizations can build pipelines that are reliable, scalable, and ready to support smarter decisions.
Consider reaching out to expert data scientists to help create an optimized architecture for data analysis, monitoring, and reporting for your enterprise and clients.
Related Post

RECOMMENDED POSTS


RECOMMENDED TOPICS
TAGS
- artificial intelligence
- agentic ai
- ai
- deepseek
- machine learning
- llm
- data science
- saas
- ai/ml
- growth engineering
- chatgpt
- gpt
- openai
- ai development
- cloud management
- cloud storage
- customer expectation
- cloud optimization
- aws
- sales growth
- gcp
- social media
- social media marketing
- social influencers
- api
- application
- cybersecurity
- software engineering
- scalable architecture
- mobile development
- modular saas
- api based architecture
- deep learning
- python
- user experience
- app development
- user interface
- data analysis
- data pipeline
- generative ai
- deepfake
- healthcare
- climate change
- llm models
- leadership
- it development
- empathy
- static data
- dynamic data
- ai model
- open source
- xai
- qwenlm
- bpa
- automation
- database optimize
- modern medicine
- growth hacks
- data roles
- data analyst
- data scientist
- data engineer
- data visualization
- productivity
- database management
- sql query
- data isolation
- db expert
- artificial intelligene
- test
ABOUT
Stay ahead in the world of technology with Iowa4Tech.com! Explore the latest trends in AI, software development, cybersecurity, and emerging tech, along with expert insights and industry updates.
Comments(0)
Leave a Reply
Your email address will not be published. Required fields are marked *